
Written by Cheng Cheng, translated by Dong Wenwen
In Part-1, we have presented that GPT has to be trained distributedly, and introduced the relevant parallel techniques. Now we will compare the usability of these techniques in different frameworks (mainly in PyTorch and OneFlow).
Achilles’ Heel of PyTorch
Megatron-LM is a library specifically used for training large-scale transformer models just like GPT. All the codes are Python scripts, and the functions like operators, pipeline parallelism schedulers, communication primitives required for model parallelism are all manually programmed based on PyTorch by engineers from NVIDIA.
The use of PyTorch by Megatron-LM will be briefly introduced. This article will conclude that Megatron-LM has made the most of value in using PyTorch for distributed training. It will naturally lead to a question that is PyTorch user-friendly enough? This article will try to answer it.
A Lot of Manual Code is Needed for Pipeline Parallelism of PyTorch
PyTorch is originally designed to use on a single device, and the tensor and model script on a device are not directly related to the tensor and model script on another device. For data parallelism where the model scripts on every device are the same (symmetric), a design like PyTorch has no obvious flaws.
After the forward and backward computations are performed for the same mini-batch on each device, a unified AllReduce operation will be taken among the devices, followed by the optimizer separately on each device, and the data parallelism is achieved. This is exactly what the DDP (DistributedDataParallel) module of PyTorch does.
While as for the pipeline parallelism, the model network distributed onto each device is not the same (i.e., asymmetric), and each device executes part of the network in a relay way. And how can this kind of parallelism be supported by PyTorch?
Take the figure above as an example, it illustrates the topology of a network in pipeline parallelism. The network is divided into two stages which are distributed onto GPU 0 and GPU 1. GPU 0 and GPU 1 are executed in relay, and the output Tensor of T2 Layer on GPU 0 needs to be sent to T3 Layer on GPU 1 as an input.
When we use PyTorch to implement the network in the above figure, we need to characterize the distinct network structure for each device according to the stage it corresponds to. And the specific if statements are required in script by Megatron-LM for the first stage and last stage due to their particularity on the execution sequence.
def train_step(...):
if mpu.is_pipeline_first_stage():
unwrapped_model = model[0]
elif mpu.is_pipeline_last_stage():
unwrapped_model = model[-1]After each device is initiated and enters regular execution, Megatron-LM needs to call NCCL APIs before and after each execution: the output of the previous stage needs to be received by the current stage by calling the ncclRecv of NCCL p2p APIs (a ncclSend operation occurs in the previous stage at the same time), and calling ncclSend is required to send the output to the next stage (a ncclRecv operation occurs in the next stage at the same time).
def forward_backward_pipelining_without_interleaving(...):
# Before running 1F1B, need to receive first forward tensor.
# If all microbatches are run in warmup / cooldown phase, then no need to
# receive this tensor here.
if num_microbatches_remaining > 0:
input_tensor = p2p_communication.recv_forward(timers)
for i in range(num_microbatches_remaining):
output_tensor = forward_step(...)
if forward_only:
p2p_communication.send_forward(output_tensor, timers)
else:
output_tensor_grad = p2p_communication.send_forward_recv_backward(output_tensor, timers)
# Add input_tensor and output_tensor to end of list, then pop from the
# start of the list for backward pass.
input_tensors.append(input_tensor)
output_tensors.append(output_tensor) if forward_only:
if not last_iteration:
input_tensor = p2p_communication.recv_forward(timers)
else:
input_tensor, output_tensor = input_tensors.pop(0), output_tensors.pop(0)
input_tensor_grad = backward_step(...)
if last_iteration:
input_tensor = None
p2p_communication.send_backward(input_tensor_grad, timers)
else:
input_tensor = p2p_communication.send_backward_recv_forward(input_tensor_grad, timers)
Therefore, PyTorch users need to exactly know about when each stage needs to recv, when to send, and send to whom; they also need to know exactly for which steps, only forward computation is required (because the backward has not been ready yet), and for which steps the forward and backward computation all need to be done.
That’s why Megatron-LM has provided many send/revc APIs to users in megatron/p2p_communication.py :
def recv_forward(...):
"""Receive tensor from previous rank in pipeline (forward receive)."""def recv_backward(...):
"""Receive tensor from next rank in pipeline (backward receive)."""def send_forward(...):
"""Send tensor to next rank in pipeline (forward send)."""
def send_backward(...):
"""Send tensor to previous rank in pipeline (backward send)."""def send_forward_recv_backward(...):
"""Batched send and recv with next rank in pipeline."""
def send_backward_recv_forward(...):
"""Batched send and recv with previous rank in pipeline."""
def send_forward_recv_forward(...):
"""Batched recv from previous rank and send to next rank in pipeline."""
def send_backward_recv_backward(...):
"""Batched recv from next rank and send to previous rank in pipeline."""def send_forward_backward_recv_forward_backward(...):
"""Batched send and recv with previous and next ranks in pipeline."""
With the above discussions, we can find that if the algorithm engineer wants to leverage pipeline parallelism with PyTorch, he needs to control all the details of the pipeline, including judging whether to conduct forward computation or to conduct forward and backward computation at the same time, and scheduling the sending/receiving between different stages, which requirements are too high for users to obey.
What’s more disturbing is that PyTorch does not have a mechanism to ensure the correctness of data interaction between devices in the pipeline parallelism. This means that, before making the code efficient, it is hard to exclude the possibility of a mathematically incorrect code, since the semantic errors made by users may not be found and reported by PyTorch.
All these problems have brought great barriers to developers. Therefore, only the experts from companies like NVIDIA and Microsoft can conduct pipeline parallelism with PyTorch.
A Lot of Knowledge about Communication Primitive is Needed for Model Parallelism in PyTorch
All types of parallelisms (data-, model- and pipeline-parallelism) are needed in order to fulfill GPT’s requirement of its large-scale training. For example, a transformer layer uses both data and model parallelisms. Those are called data-parallel and tensor-model-parallel respectively in Megatron-LM and DeepSpeed. But why both? To save memory and take the advantage of the differences between high-speed interconnection’s (NVlink and NVSWitch) bandwidth and IB internet’s bandwidth, NVIDIA specifically designed a hybrid parallelism strategy that adopts data parallelism between machines and model parallelism inside each machine.
It is rather a complex problem to match different types of parallelism up with their suitable scenarios. To begin with, the amount of data transmission between devices varies when different parallelisms are adopted. Meanwhile, factors such as host-device memory bottleneck, different proportions of GPU bandwidth and network bandwidth, batch size, etc. can all influence the decision of the optimal parallelism strategy. Due to this high degree of complexity, we only focus on GPT-3 here, and the general analysis will be introduced later.
In most cases, data parallelism is the most efficient strategy. However, when dealing with a huge amount of parameters such as GPT-3, it is impossible for a single GPU to carry out such model. This is where model and pipeline parallelisms play their role. Due to the difference between NVlink and IB bandwidth,NVIDIA develops a method that divides a topology of cluster into two subgroups: one is responsible for interconnections among machines, while the other takes care the what’s happening inside each machine. More specifically, pipeline and data parallelisms are used between machines due to the relatively slow data transmission speed. On the other hand, since the data transition through built-in NVLink is faster, model parallelism is used inside each machine.
- Data Parallelism: AllReduce operator is applied during backpropagation when data parallelism is adopted. Model update in data parallelism is relatively a low-frequency operation compared to other operations when using gradient accumulation: model only updates once for multiple micro-batches, thus making it an appropriate choice to execute among machines.
- Tensor Model Parallelism: On the other hand, for (tensor) model parallelism, Megatron-LM deduces two operations inside the transformer layer, which are MLP and Self-Attention. In this type of computation, AllReduce needs to be inserted in specific locations to synchronize forward and backward operations, which should fall into the category of high-frequency operation for it occurs for every micro-batch. Consequently, tensor model parallelism is suitable for operations inside each machine.
- Pipeline Parallelism: pipeline parallelism should be used for inter-machine connection due to its low amount of data transition. This means that data only needs to be transmitted among stages. However, it is essential to divide one batch into micro-batches in order to leverage pipeline parallelism’s advantages. Also, extra device memories are needed to cache activation. Pipeline parallelism also suffers from bubble.
Megatron-LM tries to evaluate model efficiency by controlling the degree of parallelism ( model-parallel-size = tensor-model-parallel-size * pipeline-model-parallel-size) as well as distributing different sizes to model and pipeline parallelism. In an experiment, Megatron-LM concludes that the best efficiency occurs when tensor-model-parallel-size = 8. This size equals the number of GPUs inside each machine (see figure below).
Now let’s discuss the weakness of PyTorch. If you have previously dug into how Megatron-LM can be applied in GPT, you should see that to implement model parallelism, the activations data have be synchronized in both forward and backward directions with manually inserted collective communication primitives.
But where exactly to insert the communication operations? To answer this question, Megatron-LM presents that the most important step is to insert the synchronization code into the forward function, which belongs to the class RowParallelLinear.
class RowParallelLinear(torch.nn.Module):
def forward(self, input_):
output_parallel = F.linear(input_parallel, self.weight)
# All-reduce across all the partitions.
output_ = reduce_from_tensor_model_parallel_region(output_parallel)This is the most important step for data synchronization. But even in a clearly structured network like GPT, there are many operators(kernels, modules) need to be synchronized, such as:
- AllReduce:train_step, calc_params_l2_norm, CrossEntropy
- Scatter:RowParallelLinear
- AllGather:ColumnParallelLinear
- etc.
As you can probably see, facing all the lengthy codes and scripts, how exactly will one algorithm engineer be able to figure out:
- Where to apply communication operations? Although Megatron-LM has deduced where to insert communication operations in GPT’s script, users may have to re-evaluate this position if they’d like to edit the network structure (e.g. adding/changing Op, etc.).
- What types of communication operation the users should implement? Other than AllReduce, collective communication includes ReduceScatter, AllGather, Reduce, Broadcast, All2All, etc. Other than collective communication, cluster operations such as Scatter and Gather also force users to consider which Tensor dimension they should apply these operations on.
- Where to communicate with? Under data and model parallelisms, the entire GPU cluster needs to be regrouped, and data synchronization using AllReduce needs to be implemented inside each subgroup. The appropriate synchronization has to be performed before each model update. Consequently, if a GPU with a particular rank id can only communicate with some specific ranks which are in the same subgroup. Clearly, this process is complicated to be realized.
Additionally, even if communication operations are adopted, how to ensure the correctness? Unfortunately, PyTorch itself is incapable of ensuring the mathematical correctness for the distributed computation, it’s all up to the users themselves.
This is why experts from NVIDIA are able to implement Megatron using PyTorch, but most of the individual developers are only capable of using Megatron-LM/pretrain_gpt.py directly.
Thus, it is extremely hard for the common developers to apply the approaches in Megatron-LM to other models.
All the above difficulties arise from the absence of a consistent view of a distributed training. In the result, the complicated parallelism is extremely hard to be implemented, and only specific distributed network, scenario and operator can be implemented by using simple communication primitive. Actually, we can eliminate such problems by choosing an alternative path: the consistent view.
Abstract Interfaces Invented by OneFlow for Distributed DL Frameworks
OneFlow presents the concept of consistent view, which is used to simplify the use of distributed deep learning frameworks. Using Placement + SBP and consistent view, OneFlow is capable of solving complicated parallelisms in a general way.
But how exactly? Let’s take a tour of Consistent View, Placement and SBP.
Consistent View
In distributed training scenarios, OneFlow abstracts the cluster as a super computer, where users only need to design their deep learning model just like on a single device.
We name this virtual super computer and the cluster as Logical View and Physical View, respectively. In addition, OneFlow maintains the mathematical correctness and consistency of the Logical View and Physical View. This idea is called Consistent View.
Ideally, the computing capacity of this abstract super computer (Logical View) is the sum of all the computing power of each physical device (if the computing power of each physical device is fully used, the computing power of the super device increases linearly), and the memory of the super device is also the sum of the memories of the physical devices.
Placement is All You Need with Pipeline Parallelism
The concept of Placement in OneFlow describes the mapping relationship between Logical Op and Physical Op. OneFlow will automatically number machines and devices, for example, if there are 4 machines and inside each of which there are 8 GPUs, the machines will get IDs: 0, 1, 2, 3 and the devices in each machine will get IDs: 0, 1, 2, 3, 4, 5, 6, 7.
On which device the op should be placed, one only needs set the placement attribute of a logical op on OneFlow like this: placement = "0:0-7" (placed on all GPUs of machine 0).
In pipeline parallelism, it is unnecessary for users to worry about the timing of send/recv and the choice of forward/forward + backward like PyTorch.
The following is the pipeline parallelism code OneFlow uses in GPT (the code actually includes all types of parallelisms).
class Transformer(object):
def __call__(self, hidden_states):
for i in range(self.num_layers):
with distribute.layer_placement_scope(i):
h = self.layers[i](h)layer_placement_scope is used to allocate placement and stage id inside a scope.
def layer_placement_scope(layer_idx, device="gpu"):
dist_util = get_dist_util()
with flow.scope.placement(
device, dist_util.get_layer_placement(layer_idx), dist_util.parallel_hierarchy,
):
if dist_util.is_pipeline_parallel():
with flow.experimental.scope.config(
pipeline_stage_id_hint=dist_util.get_layer_stage(layer_idx)
):The above figure illustrates a possible placement, which can be used to enable pipeline parallelism between GPU0 and GPU1. It can also be found that the operators CopyH2D and CopyD2D are responsible for the data transitions between CPUs and GPUs, and they are automatically inserted by OneFlow.
Other details about pipeline parallelism such as how stages communicate, forward/backward, how to run, and how to ensure correctness are all taken cared by OneFlow but the users (the internal mechanism about the functions above of OneFlow, will be introduced in the next article).
SBP is All you Need with Data or Model Parallelism
SBP is a concept invented by OneFlow to describe the mapping relation between logical tensor and physical tensors. It is short for “Split”, “Broadcast”, and “Partial”.
Let’s explain it in more detail:
- Split: Split means that multiple physical tensors is obtained by splitting a logical tensor along a particular dimension. Split includes a parameter specifying the axis, which indicates the dimension of the splitting process. The logical tensor can be re-obtained by concatenating the physical tensors.
- Broadcast: Broadcast means that multiple physical tensors are exactly a copy of the logical tensor. The data of the two types of tensor are equivalent.
- Partial: Take PartialSum as an example, it reveals the fact that the shape of both types of tensors is the same, but each value in the physical tensor is a part of the value in the corresponding position of the logical tensor. If we take the sum of all the elements in the same position of the physical tensors, the original logical tensor will be obtained. The same applies to other reduce operation like min, max, etc.
The following figure illustrates the basic idea of SBP:
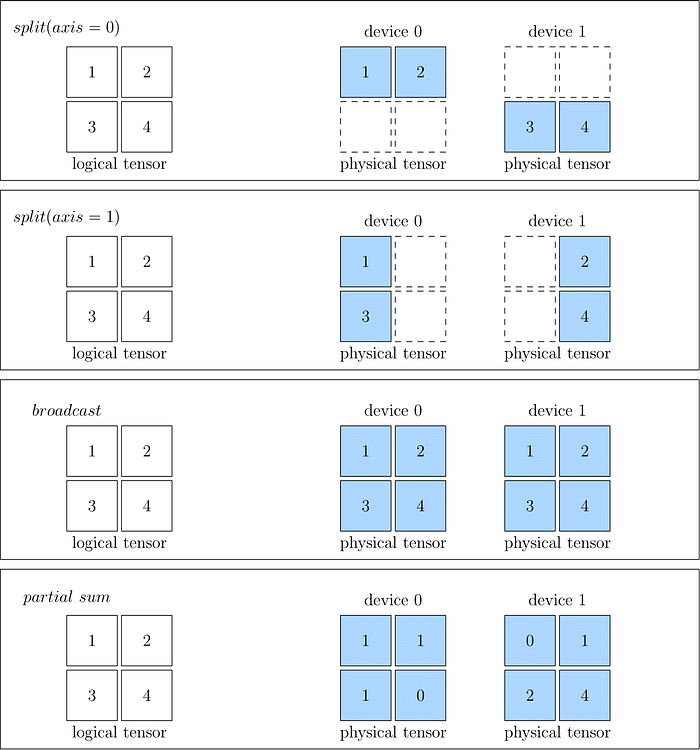
It is important to realize that there may exist in multiple valid SBP configurations for a same logical tensor. For each SBP configuration, the physical tensors demonstrate a particular mapping relations to the logical tensor. The relations depend on the operators which produces and consumes the their corresponding physical tensors. The relations also depend on how operators interact with their logical tensors.
So what does the user have to do in order to use OneFlow to implement data parallelism or model parallelism? In fact, setting SBP for variable is all they need. Let’s introduce ways to deploy data and model parallelisms using OneFlow.
For data parallelism, as we know, the models of each device is the same. Thus, Broadcast will be used, and setting the SBP attribute of model variable to Broadcast is the only thing users need to do to run networks with data parallelism. (Of course, the data tensor uses Split along the batch dimension).
All other synchronization steps such as AllReduce are automatically inserted at compile time and executed at run time by OneFlow for data parallelism.
By contrast, for model parallelism, the only thing users need to do is setting the SBP attribute of model variable to Split(0), which means that the model sub-matrix on each physical device is obtained by splitting the original model matrix. (Of course, the data tensor uses Broadcast in this case).
In addition, in a Linear Layer (with the premise of row major storage), both Split(0) and Split(1) are capable of splitting the matrix. We choose Split(0) because if Split(1) is implemented, AllGather has to be used instead of AllReduce. The AllReduce operations in PyTorch would require specific manual code. However, through Oneflow, they can be automatically deduced.
Finally, the consistent view mechanism of OneFlow is able to ensure the mathematical correctness of distributed operation even with a poor performance for choosing an appropriated SBP configuration. Clearly, PyTorch is incapable of accomplishing such a goal.
2-D SBP and Hybrid Parallelism
OneFlow also supports 2-D SBP, which is the key to achieve the goal of implementing Hybrid Parallelism (both data and model parallelism at the same time).
The figure below demonstrates 2-D SBP(using [Split(0), Split(1)]) on a cluster with two machines, each with 2 GPUs. The GPUs are represented as a (2 x 2) matrix.
Assuming users want to carry out hybrid parallelism, one can simply alter the variable code in 2-D SBP as [Broadcast, Split(0)]. Let's explain it with the figure below.
As we can see, in the first dimension of Broadcast, the pairs of GPUs ({group 0, device 0} and {group 1, device 0}, {group 0, device 1} and {group 1, device 1}) are interacting with each other with data parallelism, and in the second dimension of Split(0), {group 0, device 0} and {group 1, device 0} are executing with model parallelism(The same goes for {group 0, device 1} and {group 1, device 1}).
In OneFlow, 2-D SBP is just a list of two SBP configuration values(such as [Broadcast, Split(0)]). Thus, users can easily manipulate with the types of parallelsim by making simple changes to SBP.
OneFlow Provides the Correct Level of Abstraction
To sum up the contrast between PyTorch and OneFlow, we can arrive to the following conclusions:
PyTorch’s incapabilities
- PyTorch can only examine the entire training model physically but not logically (no Consistent View).
- PyTorch still has not decoupled the communication operations with network structures.
- Users have to schedule devices manually with asymmetric parallelism such as pipeline parallelism。
- PyTorch cannot ensure model correctness and mathematical consistency among machines.
All of the above raises the entry barrier of training complex parallel models, which is why most people developing PyTorch versions of GPT are experts in giant corporations such as NVIDIA and Microsoft.
OneFlow’s Advantages
- Through consistent view, users no longer have to worry about the manual details when implementing parallelisms.
- Through the method of Placement + SBP, OneFlow successfully relieves difficulties in any parallelism scenarios.
- OneFlow’s communication logic in cluster is automatically managed by OneFlow, independent of operators and networks.
- OneFlow ensures the parallelism and topology cluster correctness mathematically when training.
Thus, we can claim that OneFlow provides the correct level of abstraction. It reduces the number of challenges an algorithm engineer has to encounter when training parallel models.
With sufficient hardware resources, we confidently claim that using OneFlow, any algorithm engineer can train not only GPT but a new huge model as well.
Related articles:
Welcome to visit OneFlow on GitHub and follow us on Twitter and LinkedIn.
Also, welcome to join our Discord group to discuss and ask OneFlow related questions, and connect with OneFlow contributors and users all around the world.
