
Written by Zhang Xiaoyu; Translated by Dong Wenwen, Wang Kaiyan
The project shared in this article is what I’m doing in OneFlow recently: port PyTorch FX to OneFlow and obtain automatic quantization aware training Dynamic computation graph (which is called nn.Module in Pytorch and OneFlow). At present, based on the
nn.Modulebuilt by themselves, users can complete the complete process fromnn.Modulequantization aware training to using TensorRT to deploy the model after quantization aware training to the GPU with few modification of the code. The process of TensorRT inference is: Oneflow dynamic computation graph (nn.Module)->OneFlow quantization aware training model (nn.Module)->OneFlow static computation graph (nn.Graph)->ONNX-> TensorRT. Quantization aware training is based on the FX module that supports writing Pass in Eager (FX was first proposed by PyTorch, and the author ported its infrastructure to OneFlow).
0x0. Introduction
Most of you have known or used deep learning frameworks such as Pytorch, TensorFlow or OneFlow (which the author is participating in the development). You will be interested in this article if you feel that it is too perplexing when getting in touch with the quantitative schemes of the deep learning frameworks.
In this article, I will start with PyTorch’s two generations of quantitative schemes to discuss their strengths and weaknesses. Then I will talk about the quantization aware training of OneFlow that combines PyTorch’s FX module and some of my own ideas. Here are the contents in this article:
- PyTorch’s FX module
- Eager Pass
- Quantization Aware Training
- Fusion of Conv and BN
- Conversion of nn.Module and nn.Graph in OneFlow
- ONNX
- TensorRT
It doesn’t matter if you are not familiar with any of the above points. In fact, you can quickly get started with the quantization aware training mentioned in this article even if you can only build the model using PyTorch. Because the codes of quantization aware training, the model transformed into ONNX and the code of using TensorRT to deploy have been open-sourced in the OneFlow’s community.
Users can build a dynamic graph model based on OneFlow (i.e. nn.Module), with the almost same API of the operator as that of PyTorch. Then call the following lines of code to make this dynamic graph model (the nn.Module) automatically insert quantization modules at the appropriate position to generate a quantization model (the nn.Module). And conduct the quantization aware training based on this quantization model.
gm: flow.fx.GraphModule = flow.fx.symbolic_trace(net)
qconfig = {
'quantization_bit': 8,
'quantization_scheme': "symmetric",
'quantization_formula': "cambricon",
'per_layer_quantization': True,
'momentum': 0.95,
}net = quantization_aware_training(gm, flow.randn(1, 3, 32, 32), qconfig)
net = net.to(device)
After the training is completed, call the following code to complete the conversion of the trained quantization model to ONNX, and use TensorRT to perform inference on the GPU.
quantization_resnet18 = quantization_aware_training(gm, flow.randn(1, 3, 32, 32).to("cuda"), qconfig)
quantization_resnet18 = quantization_resnet18.to("cuda")
quantization_resnet18.eval()
checkpoint = flow.load('/home/zhangxiaoyu/oneflow-cifar/checkpoint/epoch_11_val_acc_83.280000')
quantization_resnet18.load_state_dict(checkpoint)origin_gm: flow.fx.GraphModule = flow.fx.symbolic_trace(resnet18)
dequantization_resnet18 = dequantization_aware_training(origin_gm, gm, flow.randn(1, 3, 32, 32).to("cuda"), qconfig)
dequantization_resnet18 = dequantization_resnet18.to("cuda")
dequantization_resnet18.eval()class ResNet18Graph(flow.nn.Graph):
def __init__(self):
super().__init__()
self.m = dequantization_resnet18def build(self, x):
out = self.m(x)
return outdef test_resnet():
resnet_graph = ResNet18Graph()
resnet_graph._compile(flow.randn(1, 3, 32, 32).to("cuda"))
with tempfile.TemporaryDirectory() as tmpdirname:
flow.save(dequantization_resnet18.state_dict(), tmpdirname)
convert_to_onnx_and_check(resnet_graph, flow_weight_dir=tmpdirname, onnx_model_path="/tmp", print_outlier=True)
ipt_dict, onnx_res = run_onnx("/tmp/model.onnx", get_onnx_provider("cpu"))
trt_res = run_tensorrt("/tmp/model.onnx", ipt_dict[list(ipt_dict.keys())[0]])
compare_result(onnx_res, trt_res, atol=1e-4, print_outlier=True)test_resnet()
- OneFlow FX(infrastructure for realizing quantization aware training): https://github.com/Oneflow-Inc/oneflow/pull/5939
- OneFlow Cifar (quantization training of Cifar10 based on OneFlow FX): https://github.com/BBuf/oneflow-cifar
- OneFlow->ONNX and TensorRT: https://github.com/Oneflow-Inc/oneflow_convert/pull/45
Users can complete the entire process of end-to-end quantization aware training to GPU deployment using just the tens of lines of code, which I think is interesting and concise! All the code of this project is open-sourced in OneFlow’s community, and the corresponding links are shown below.
0x1. Development of PyTorch’s Quantization Schemes
This chapter is mainly based on PyTorch’s official documentation https://pytorch.org/docs/1.9.0/quantization.html. PyTorch’s first generation of quantization mode is Eager Mode Quantization, and FX Graph Mode Quantization was introduced in 1.8. Eager Mode Quantization requires the users to change the model and specify the operators to be fused manually, while FX Graph Mode Quantization realizes automatic quantization: users do not need to modify the model manually and care about internal operations. This change is specifically shown in the following figure.
The following is the difference between these two quantization schemes.
Eager Mode Quantization
class Net(nn.Module):def __init__(self, num_channels=1):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(num_channels, 40, 3, 1)
self.conv2 = nn.Conv2d(40, 40, 3, 1)
self.fc = nn.Linear(5*5*40, 10)def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2, 2)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2, 2)
x = x.reshape(-1, 5*5*40)
x = self.fc(x)
return x
In the foward of nn.Module, Pytorch is able to construct the network, call other nn.Module, call nn.functional.xxx, and even write the control logic like if. But this also brings a problem that the graph structure of this model is difficult to obtain at the Eager level. So in Eager Mode Quantization, to quantify the network, it must be modified manually:
class NetQuant(nn.Module):def __init__(self, num_channels=1):
super(NetQuant, self).__init__()
self.conv1 = nn.Conv2d(num_channels, 40, 3, 1)
self.relu1 = nn.ReLU()
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(40, 40, 3, 1)
self.relu2 = nn.ReLU()
self.pool2 = nn.MaxPool2d(2, 2)
self.fc = nn.Linear(5*5*40, 10)self.quant = torch.quantization.QuantStub()
self.dequant = torch.quantization.DeQuantStub()def forward(self, x):
x = self.quant(x)
x = self.relu1(self.conv1(x))
x = self.pool1(x)
x = self.relu2(self.conv2(x))
x = self.pool2(x)
x = x.reshape(-1, 5*5*40)
x = self.fc(x)
x = self.dequant(x)
return x
In other words, in addition to Conv and Linear modules that contain parameters, ReLU and MaxPool2d must also be defined in __init__ to be processed correctly in Eager Mode Quantization. In addition, there are some cases that require fuse before quantization, such as Conv+ReLU. These layers also need to be specified manually. Currently, Eager Mode Quantization supports the fusion of ConV + BN, ConV + BN + ReLU, Conv + ReLU, Linear + ReLU, BN + ReLU.
model = NetQuant()model.qconfig = torch.quantization.get_default_qconfig('fbgemm')
modules_to_fuse = [['conv1', 'relu1'], ['conv2', 'relu2']] # Specify the layer to be merged
model_fused = torch.quantization.fuse_modules(model, modules_to_fuse)
model_prepared = torch.quantization.prepare(model_fused)
post_training_quantize(model_prepared, train_loader) # Post training quantization
model_int8 = torch.quantization.convert(model_prepared)FX Graph Mode Quantization
The introduction to the PyTorch FX module is in the next chapter.
Since PyTorch FX can automatically track the code in the forward, it records every node in the network. It is much stronger than the Eager mode in terms of fuse and dynamic insertion of quantization nodes. Therefore, for the code above, we don’t need to modify the network manually, bust only need to use FX to help us modify the network automatically. Here is an example:
from torch.quantization import get_default_qconfig, quantize_jit
from torch.quantization.quantize_fx import prepare_fx, convert_fx
model = Net()
qconfig = get_default_qconfig("fbgemm")
qconfig_dict = {"": qconfig}
model_prepared = prepare_fx(model, qconfig_dict)
post_training_quantize(model_prepared, train_loader) # Post training quantization
model_int8 = convert_fx(model_prepared)From the above explanation of the two sets of quantization approaches, the FX Graph Mode Quantization is obviously better. Because it does not require users to make additional restrictions when defining the model, instead, users can write the code as they like. OneFlow’s quantization aware training is also based on the FX module.
In the project of TensorRT https://github.com/NVIDIA/TensorRT/tree/master/tools/pytorch-quantization, we can find that Eager Mode Quantization is still used to convert to ONNX in PyTorch.
0x2. OneFlow FX (Write Pass in Eager)
What can FX use to do?
FX can transform a nn.Module to another nn.Module by implementing Transformation (also called Pass) on this architecture. For example, inset fake quantization nodes after Conv automatically to implement quantization training, then generate GraphModule (a nn.Module) to train and convert it to ONNX for deployment.
The OneFlow’s FX module is implemented in this PR: https://github.com/Oneflow-Inc/oneflow/pull/5939, which reuses the core logic and code of PyTorch's FX infrastructure. The works in this PR include:
- Streamline the special design of PyTorch FX, such as the Trace to _C, and the interaction with Jit. Retain the four core functions of PyTorch FX, namely Symbolic Tracing, Intermediate Representation, Transformation and Python Codegen.
- Write the code to realize the above four functions and to fully adapt to the related design of OneFlow at the same time. Use
import oneflow.fxto experience these functions. We can trace the structure of nearly all Eager models built by the OneFlow API and transform them into another equivalentnn.Module. We can also customize our own Transformation Pass on the basis of thisnn.Module. - Test of AlexNet, ResNet50, MobileNetV2 and other models.
Now, let’s see the whole idea of OneFlow FX.
Here is a simple demonstration:
import oneflow
# Simple module for demonstration
class MyModule(oneflow.nn.Module):
def __init__(self):
super().__init__()
self.param = oneflow.nn.Parameter(oneflow.rand(3, 4))
self.linear = oneflow.nn.Linear(4, 5)
def forward(self, x):
return self.linear(x + self.param).clamp(min=0.0, max=1.0)
module = MyModule()
from oneflow.fx import symbolic_trace
# Symbolic tracing frontend - captures the semantics of the module
symbolic_traced : oneflow.fx.GraphModule = symbolic_trace(module)
# High-level intermediate representation (IR) - Graph representation
print(symbolic_traced.graph)
"""
graph():
%x : [#users=1] = placeholder[target=x]
%param : [#users=1] = get_attr[target=param]
%add : [#users=1] = call_function[target=operator.add](args = (%x, %param), kwargs = {})
%linear : [#users=1] = call_module[target=linear](args = (%add,), kwargs = {})
%clamp : [#users=1] = call_method[target=clamp](args = (%linear,), kwargs = {min: 0.0, max: 1.0})
return clamp"""
# Code generation - valid Python code
print(symbolic_traced.code)
"""
def forward(self, x):
param = self.param
add = x + param; x = param = None
linear = self.linear(add); add = None
clamp = linear.clamp(min = 0.0, max = 1.0); linear = None
return clamp
"""
The Proxy class in FX will wrap all the functions and common magic functions in call_method, call_function and math libraries in OneFlow to record all the operators in OneFlow, which is done when writing import oneflow.fx. Then when passing in a nn.Module and calling symbolic_trace to trace code, other nn.Module in __init__ will be processed first. These nn.Module and the input data should be wrapped by Proxy.
After wrapping all the operators that exist in the program by Proxy, perform forward again. In this way, the input data of this forward is no longer Tensor but Proxy (Tensor). Since the execution process of the program is similar to the process of pushing and popping of an operator, we can directly unpack the data and op recorded by the Proxy in this execution order. After unpacking, we can get the real Tensor, Parameter And operators, etc., and we use these data and operators as points and edges to construct a new Graph. So how is Graph transformed into a nn.Module? FX holds this Graph by introducing the data structure of GraphModule. In addition, GraphModule also holds code and foward, both of which are automatically generated based on Graph.GraphModule is still a nn.Module.
The automatically generated code is the code in the GraphModule, and printing the code is actually the complete execution process of the entire forward function.
In addition, FX also provides an Interpreter class to allow users to customize the execution process of nn.Module. For example, in this PR, a Pass that derives all intermediate Tensor shapes based on this class is provided. In addition, a Pass that visualizes the structure of GraphModule based on pydot is also provided, as shown in the figure below.
Here, I believe that most of you have had a general understanding of FX. One of the best features of FX is that we can modify nn.Module and then return to the changed nn.Module. Moreover, it is not difficult to find that the quantization aware training is to replace components such as Conv+BN, Conv and Linear with components inserted with fake quantization nodes. So we can accomplish this by writing a Pass based on FX.
The question at the beginning of this chapter can be answered that FX supports writing Pass in Eager.
However, FX also has shortcomings that it is unable to process control flow (but this has little effect because users generally don’t deploy the network that contains control flow).
0x3. Obtain Quantization Aware Training Pass
With OneFlow FX, we can obtain a pass for quantization aware training to automatically insert the quantization aware training component into the user-defined network to complete the quantization aware training.
Take ResNet18 as an example, which only has the Conv+BN mode, that is, any convolutional layer is followed by a BN layer. Conv will also be fused with BN by TensorRT during inference. Therefore, we must also fuse Conv and BN during training to avoid the affected accuracy of deployment. So, we need to fuse the parameters of the BN layer and the convolutional layer, and then quantify this fused parameter. The specific process is shown in the figure below.
The following is the formula of fusing Conv and BN:
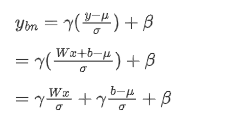
So:
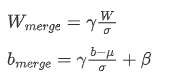
where W and b represent the weight and bias of the convolutional layer, and x and y represent the input and output of the convolutional layer. The weight and bias after fusing the batchnorm parameters Wmerge and bmerge can be derived based can be derived based on the calculation formula of BN.
The quantization aware training component after the fusion of Conv+BN can be obtained based on the above formula. I marked the difference between the training and inference in the code.
class QConvBN(flow.nn.Module):
def __init__(
self,
conv_module,
bn_module,
quantization_bit=8,
quantization_scheme="symmetric",
quantization_formula="google",
per_layer_quantization=True,
momentum=0.95,
):
super().__init__()
self.quantization_bit = quantization_bit
self.quantization_scheme = quantization_scheme
self.quantization_formula = quantization_formula
self.per_layer_quantization = per_layer_quantization
self.conv_module = conv_module
self.bn_module = bn_moduleself.moving_min_max_observer = flow.nn.MovingAverageMinMaxObserver(
training=self.training,
quantization_formula=quantization_formula,
stop_update_after_iters=1,
quantization_bit=quantization_bit,
quantization_scheme=quantization_scheme,
momentum=momentum,
)self.min_max_observer = flow.nn.MinMaxObserver(
quantization_formula=quantization_formula,
quantization_bit=quantization_bit,
quantization_scheme=quantization_scheme,
per_layer_quantization=per_layer_quantization,
)self.fake_quantization = flow.nn.FakeQuantization(
quantization_formula=quantization_formula,
quantization_bit=quantization_bit,
quantization_scheme=quantization_scheme,
)def fold_bn(self, mean, std):
if self.bn_module.affine:
gamma_ = self.bn_module.weight / std
weight = self.conv_module.weight * gamma_.view(
self.conv_module.out_channels, 1, 1, 1
)
if self.conv_module.bias is not None:
bias = (
gamma_ * self.conv_module.bias - gamma_ * mean + self.bn_module.bias
)
else:
bias = self.bn_module.bias - gamma_ * mean
else:
gamma_ = 1 / std
weight = self.conv_module.weight * gamma_
if self.conv_module.bias is not None:
bias = gamma_ * self.conv_module.bias - gamma_ * mean
else:
bias = -gamma_ * meanreturn weight, biasdef forward(self, x):
scale, zero_point = self.moving_min_max_observer(
x, flow.tensor([0], dtype=flow.int64).to(x.device.type)
)
x = self.fake_quantization(x, scale, zero_point)
if self.training:
y = flow.nn.functional.conv2d(
x,
self.conv_module.weight,
self.conv_module.bias,
stride=self.conv_module.stride,
padding=self.conv_module.padding,
dilation=self.conv_module.dilation,
groups=self.conv_module.groups,
)
y = y.permute(1, 0, 2, 3) # NCHW -> CNHW
y = y.view(self.conv_module.out_channels, -1) # CNHW -> C,NHW
mean = y.mean(1)
var = y.var(1)
with flow.no_grad():
self.bn_module.running_mean = (
self.bn_module.momentum * self.bn_module.running_mean
+ (1 - self.bn_module.momentum) * mean
)
self.bn_module.running_var = (
self.bn_module.momentum * self.bn_module.running_var
+ (1 - self.bn_module.momentum) * var
)
else:
mean = flow.Tensor(self.bn_module.running_mean)
var = flow.Tensor(self.bn_module.running_var)std = flow.sqrt(var + self.bn_module.eps)
weight, bias = self.fold_bn(mean, std)weight_scale, weight_zero_point = self.min_max_observer(weight)
res = flow.nn.functional.conv2d(
x,
self.fake_quantization(weight, weight_scale, weight_zero_point),
bias,
stride=self.conv_module.stride,
padding=self.conv_module.padding,
dilation=self.conv_module.dilation,
groups=self.conv_module.groups,
)
return res
After implementing this component, we can obtain a Pass for quantization aware training by replacing the Conv+BN in the user's nn.Module calculation graph with this QConvBN component. The code of the replacement is shown below:
for x in gm.graph.nodes:
if x.target in insert_place:
with gm.graph.inserting_after(x):
y = x.next
if (
isinstance(insert_op_state[x.target], flow.nn.Conv2d)
and y.target in insert_place
and isinstance(insert_op_state[y.target], flow.nn.BatchNorm2d)
):
now_target = get_current_module_space(x.target)
if now_target == "":
now_target = f"fake_conv_bn.{cnt}"
else:
now_target = (
f"{get_current_module_space(x.target)}.fake_conv_bn.{cnt}"
)
gm.add_submodule(
now_target,
QConvBN(
insert_op_state[x.target],
insert_op_state[y.target],
quantization_bit,
quantization_scheme,
quantization_formula,
per_layer_quantization,
momentum,
),
)
y.replace_all_uses_with(x)
gm.graph.erase_node(y)
gm.delete_submodule(y.target)
qconvbn = gm.graph.call_module(module_name=now_target, args=x.args,)
cnt = cnt + 1
x.replace_all_uses_with(qconvbn)
gm.graph.erase_node(x)
gm.delete_submodule(x.target)Find the Conv+BN component in gm (GraphModule traced from ResNet18, which is still a nn.Module), delete it and replace it with the QConvBN component.
0x4. Quantization Aware Training of Cifar10 Based On ResNet18
We can conduct quantization aware training on the customized model based on the quantization Pass obtained above. Taking ResNet18 as an example, we can add the following lines of code to the original dynamic computation graph:
gm: flow.fx.GraphModule = flow.fx.symbolic_trace(net)
qconfig = {
'quantization_bit': 8,
'quantization_scheme': "symmetric",
'quantization_formula': "cambricon",
'per_layer_quantization': True,
'momentum': 0.95,
}net = quantization_aware_training(gm, flow.randn(1, 3, 32, 32), qconfig)
net = net.to(device)
The qconfig allows users to easily configure every quantization modes supported by OneFlow.
The first net is the user-defined dynamic computation graph. The new net obtained after the Pass has been automatically inserted into the quantization aware training component. The processes of other training and testing are exactly the same as the training of FP32, which will not be introduced in detail here. I trained several quantization configurations supported by OneFlow on Cifar10 based on ResNet18, the Epochs are 200 with the same super parameters. The results are as follows:
Note:
The `momentum` parameter in the `MovingAverageMinMaxObserver` class defaults to 0.95, which will not be changed in the following experiments.
## Accuracy
| Model | quantization_bit | quantization_scheme | quantization_formula | per_layer_quantization | Acc |
| ----------------- | ----------- | ----------- | ----------- | ----------- | ----------- |
| ResNet18 | 8 | symmetric | google | True | 95.19% |
| ResNet18 | 8 | symmetric | google | False | 95.24% |
| ResNet18 | 8 | affine | google | True | 95.32% |
| ResNet18 | 8 | affine | google | False | 95.30% |
| ResNet18 | 8 | symmetric | cambricon | True | 95.19% |Project address: https://github.com/BBuf/oneflow-cifar.
The accuracy of ResNet18 trained on Cifar10 and based on Cifar10 is: 95.62%. Here, the quantization aware training accuracy under quantization parameters is the same as the original accuracy. The cambricon above represents the quantization scheme of Cambricon, and google represents the quantization scheme of Google.
0x5. Rewrite the Original Model Based On the Quantization Aware Training Model
We have conducted quantization aware training based on the quantization aware training model above, and now we have to consider how to deploy this quantization aware training model. Obviously, this model is not what we expected, because the model BN we used for deployment should have been merged into the convolutional layer instead of being retained. So we need to rewrite the original model based on the parameters of the quantization aware training model, and then use it to convert ONNX to TensorRT.
Similar to quantization aware training, we obtain a dequantization Pass, which is used to replace the QConvBN component with a DConv2d component. The code of the DConv2d component is shown as follows:
class DConv2d(flow.nn.Conv2d):
def __init__(
self,
in_channels,
out_channels,
kernel_size,
stride,
padding,
dilation,
groups,
quantization_bit=8,
quantization_scheme="symmetric",
quantization_formula="google",
per_layer_quantization=True,
momentum=0.95,
) -> None:
super(DConv2d, self).__init__(
in_channels, out_channels, kernel_size, stride, padding, dilation, groups
)self.moving_min_max_observer = flow.nn.MovingAverageMinMaxObserver(
training=self.training,
quantization_formula=quantization_formula,
stop_update_after_iters=1,
quantization_bit=quantization_bit,
quantization_scheme=quantization_scheme,
momentum=momentum,
)self.min_max_observer = flow.nn.MinMaxObserver(
quantization_formula=quantization_formula,
quantization_bit=quantization_bit,
quantization_scheme=quantization_scheme,
per_layer_quantization=per_layer_quantization,
)self.fake_quantization = flow.nn.FakeQuantization(
quantization_formula=quantization_formula,
quantization_bit=quantization_bit,
quantization_scheme=quantization_scheme,
)self.register_buffer("new_zero", flow.Tensor(1))
self.new_zero.fill_(0)def forward(self, x):
scale, zero_point = self.moving_min_max_observer(
x, self.new_zero.to(flow.int64).to(x.device.type)
)
x = self.fake_quantization(x, scale, zero_point)
return flow.nn.functional.conv2d(
x,
self.weight,
self.bias,
stride=self.stride,
padding=self.padding,
dilation=self.dilation,
groups=self.groups,
)
Then we only need to replace the Conv+BN in the original ResNet18 model with this component. Please note that the weight and bias of this component and the moving_min/max parameter of moving_min_max_observer should be assigned to the weight and bias corresponding to the QConvBN component and the moving_min/max parameter of moving_min_max_observer moving_min/max parameter of the trained quantization aware model .
The core parts of the dequantization Pass are as follows:
for x in origin_gm.graph.nodes:
if x.target in insert_place:
with origin_gm.graph.inserting_after(x):
y = x.next
if (
isinstance(insert_op_state[x.target], flow.nn.Conv2d)
and y.target in insert_place
and isinstance(insert_op_state[y.target], flow.nn.BatchNorm2d)
):
now_target = get_current_module_space(x.target)
if now_target == "":
now_target = f"fake_conv_bn.{cnt}"
else:
now_target = (
f"{get_current_module_space(x.target)}.fake_conv_bn.{cnt}"
)dequanzation_conv = DConv2d(
quantization_op_state[now_target].conv_module.in_channels,
quantization_op_state[now_target].conv_module.out_channels,
quantization_op_state[now_target].conv_module.kernel_size,
quantization_op_state[now_target].conv_module.stride,
quantization_op_state[now_target].conv_module.padding,
quantization_op_state[now_target].conv_module.dilation,
quantization_op_state[now_target].conv_module.groups,
quantization_bit,
quantization_scheme,
quantization_formula,
per_layer_quantization,
momentum,
)
mean = flow.Tensor(quantization_op_state[now_target].bn_module.running_mean)
var = flow.Tensor(quantization_op_state[now_target].bn_module.running_var)
std = flow.sqrt(var + quantization_op_state[now_target].bn_module.eps)if quantization_op_state[now_target].bn_module.affine:
gamma_ = quantization_op_state[now_target].bn_module.weight / std
weight = quantization_op_state[now_target].conv_module.weight * gamma_.view(
quantization_op_state[now_target].conv_module.out_channels, 1, 1, 1
)
if quantization_op_state[now_target].conv_module.bias is not None:
bias = (
gamma_ * quantization_op_state[now_target].conv_module.bias - gamma_ * mean + quantization_op_state[now_target].bn_module.bias
)
else:
bias = quantization_op_state[now_target].bn_module.bias - gamma_ * mean
else:
gamma_ = 1 / std
weight = quantization_op_state[now_target].conv_module.weight * gamma_
if quantization_op_state[now_target].conv_module.bias is not None:
bias = gamma_ * quantization_op_state[now_target].conv_module.bias - gamma_ * mean
else:
bias = -gamma_ * meandequanzation_conv.weight = flow.nn.Parameter(weight)
dequanzation_conv.bias = flow.nn.Parameter(bias)
dequanzation_conv.moving_min_max_observer.moving_max = quantization_op_state[now_target].moving_min_max_observer.moving_max
dequanzation_conv.moving_min_max_observer.moving_min = quantization_op_state[now_target].moving_min_max_observer.moving_minorigin_gm.add_submodule(
now_target,
dequanzation_conv,
)
y.replace_all_uses_with(x)
origin_gm.graph.erase_node(y)
origin_gm.delete_submodule(y.target)
qconvbn = origin_gm.graph.call_module(module_name=now_target, args=x.args,)
cnt = cnt + 1
x.replace_all_uses_with(qconvbn)
origin_gm.graph.erase_node(x)
origin_gm.delete_submodule(x.target)
The fusion of Conv and BN is conducted manually and the weight and bias after the fusion are assigned to the DConv2d component.
0x6. Convert to ONNX & TensorRT Inference
Based on the quantization aware training model and the dequantization Pass, we can obtain the nn.Module for inference. Then convert this nn.Module into ONNX and then put it in TensorRT for inference. Click https://github.com/Oneflow-Inc/oneflow_convert/blob/add_fx_train_quantization/examples/oneflow2onnx/quantization/test_resnet18.py for a demonstration. Here we will explain the core part of it.
# Load the weight of the trained quantization model
quantization_resnet18 = quantization_aware_training(gm, flow.randn(1, 3, 32, 32).to("cuda"), qconfig)
quantization_resnet18 = quantization_resnet18.to("cuda")
quantization_resnet18.eval()
checkpoint = flow.load('/home/zhangxiaoyu/oneflow-cifar/checkpoint/epoch_11_val_acc_83.280000')
quantization_resnet18.load_state_dict(checkpoint)# Rewrite the original model based on the quantization aware training model
origin_gm: flow.fx.GraphModule = flow.fx.symbolic_trace(resnet18)
dequantization_resnet18 = dequantization_aware_training(origin_gm, gm, flow.randn(1, 3, 32, 32).to("cuda"), qconfig)
dequantization_resnet18 = dequantization_resnet18.to("cuda")
dequantization_resnet18.eval()# nn.Graph is the bridge to convert to ONNX
class ResNet18Graph(flow.nn.Graph):
def __init__(self):
super().__init__()
self.m = dequantization_resnet18def build(self, x):
out = self.m(x)
return out
# Test Function
def test_resnet():
resnet_graph = ResNet18Graph()
resnet_graph._compile(flow.randn(1, 3, 32, 32).to("cuda"))
with tempfile.TemporaryDirectory() as tmpdirname:
flow.save(dequantization_resnet18.state_dict(), tmpdirname)
convert_to_onnx_and_check(resnet_graph, flow_weight_dir=tmpdirname, onnx_model_path="/tmp", print_outlier=True)
ipt_dict, onnx_res = run_onnx("/tmp/model.onnx", get_onnx_provider("cpu"))
trt_res = run_tensorrt("/tmp/model.onnx", ipt_dict[list(ipt_dict.keys())[0]])
compare_result(onnx_res, trt_res, atol=1e-4, print_outlier=True)test_resnet()
First, we use the dequantization Pass to rewrite the original model and change the weight in this Pass synchronously. Then we convert the model that needs to be deployed (a nn.Module) into a static computation graph through OneFlow's nn.Graph. For the documentation of nn.Graph, see https://docs.oneflow.org/master/basics/08_nn_graph.html.
Because OneFlow’s tool for converting to ONNX is based on static computation graphs, nn.Graph is necessary. It doesn't matter if you don't want to understand the principle, the complete usage has been shown above.
The following packages need to be installed to use the OneFlow->ONNX conversion tool:
python>=3.5
onnx>=1.8.0
onnxruntime>=1.6.0
oneflow>=0.5.0Run pip install oneflow_onnx.
Then call the convert_to_onnx_and_check API in oneflow_onnx to convert the quantization training model to ONNX. The figure below shows the ResNet18 converted into ONNX after quantization aware training.
We should use TesnsorRT to run this model, and also configure some environments. We need to install:
onnx>=1.8.0
onnxruntime-gpu>=1.8.0
opencv-python
pytest
nvidia-tensorrt==8.0.0.3
pycuda
flake8After these packages are installed, TensorRT can be used for inference:
ipt_dict, onnx_res = run_onnx("/tmp/model.onnx", get_onnx_provider("cpu"))
trt_res = run_tensorrt("/tmp/model.onnx", ipt_dict[list(ipt_dict.keys())[0]])
compare_result(onnx_res, trt_res, atol=1e-4, print_outlier=True)Other details can be seen in the code warehouse, here is the final result: under the same random input, the results of ONNX and TensorRT inference are basically the same:
-2.9825006 -2.9825
-5.438802 -5.4388037
3.5198674 3.5198674
2.409646 2.4096458
4.5826764 4.5826764
0.019911028 0.019910894
6.6347113 6.634712
-3.5996702 -3.5996711
-1.3407612 -1.340761
-3.8473191 -3.847319Finally, the task of deploying the original dynamic graph model to the GPU for inference after quantization aware training is completed.
0x7. Conclusion
The project shared in this article is what I’m doing in OneFlow recently: port PyTorch FX to OneFlow and obtain automatic quantization aware training Dynamic computation graph (which is called nn.Module in PyTorch and OneFlow). At present, based on the nn.Module built by themselves, users can complete the complete process from nn.Module quantization aware training to using TensorRT to deploy the model after quantization aware training to the GPU with few modification of the code. The process of TensorRT inference is: Oneflow dynamic computation graph (nn.Module)->OneFlow quantization aware training model (nn.Module)->OneFlow static computation graph (nn.Graph)->ONNX-> TensorRT. Quantization aware training is based on the FX module that supports writing Pass in Eager (FX was first proposed by PyTorch, and the author ported its infrastructure to OneFlow).
0x8. Links and Documentations for Reference
- https://docs.oneflow.org
- https://github.com/Oneflow-Inc/oneflow
- https://github.com/Oneflow-Inc/oneflow_convert
- https://github.com/BBuf/oneflow-cifar
- Introduction to Neural Network Quantification — Folding BN ReLU Code Implementation
- Realize Quantization Aware Training Based On OneFlow
I hope this article will help you in your deep learning projects😊. If you want to experience the functions of OneFlow, you can follow the method described in this article. If you have any questions or comments💡 about use, please feel free to leave a comment in the comments section below. Please do the same if you have any comments, remarks or suggestions for improvement. In future articles, we’ll introduce more functions of OneFlow, such as data type automatic promotion.
Related articles:
Welcome to visit OneFlow on GitHub and follow us on Twitter and LinkedIn.
Also, welcome to join our Discord group to discuss and ask OneFlow related questions, and connect with OneFlow contributors and users all around the world.
